AI and RAG with Gemma, Ollama, and Logi Symphony

By: Terrence Sheflin
Local LLMs are becoming mainstream with sites like HuggingFace promoting open sharing of trained LLMs. These LLMs are often very small but still extremely accurate, especially for domain-specific tasks like medicine, finance, law, and others. Gemma is a multi-purpose LLM and, while small, is competitive and accurate.
Local LLMs also have the advantage of being completely run inside your own environment. There is no chance of data leakage, and P3+ data is ensured to be secure as it never leaves the protected network. Recently Google shared its own local model: Gemma.
Gemma is a family of lightweight, state-of-the-art open models built from the same research and technology used to create the Gemini models. Developed by Google DeepMind and other teams across Google, Gemma is inspired by Gemini, and the name reflects the Latin gemma, meaning “precious stone.” Accompanying our model weights, we’re also releasing tools to support developer innovation, foster collaboration, and guide responsible use of Gemma models.
Gemma has been shared on HuggingFace, and is also available in the popular LLM hosting software Ollama. Using Ollama, Gemma, and Logi Symphony, this article will show how to quickly create a chatbot that uses RAG so you can interact with your data, locally. None of the data or questions are ever exposed to the internet or any online service outside of the local network.
Example
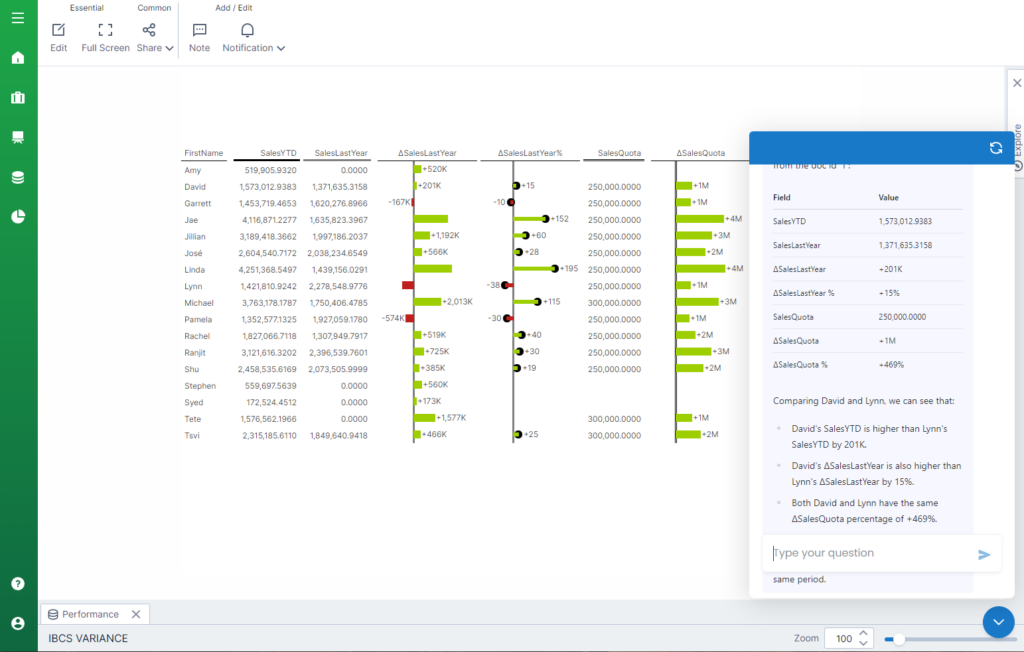
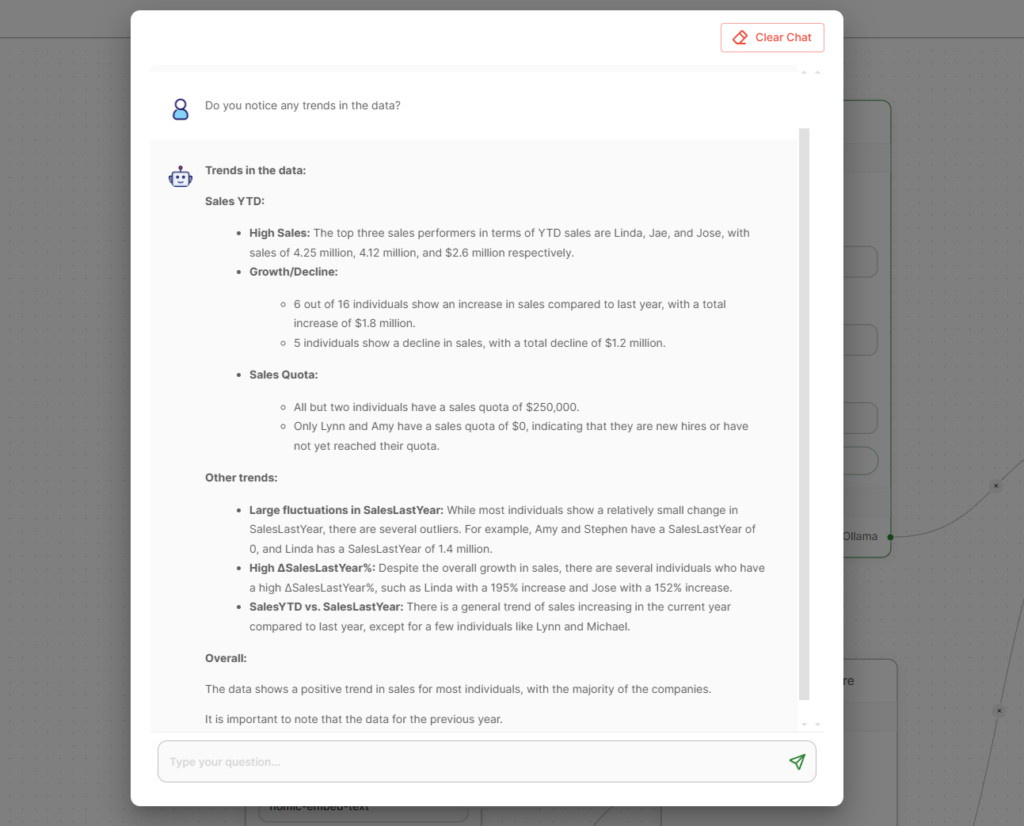
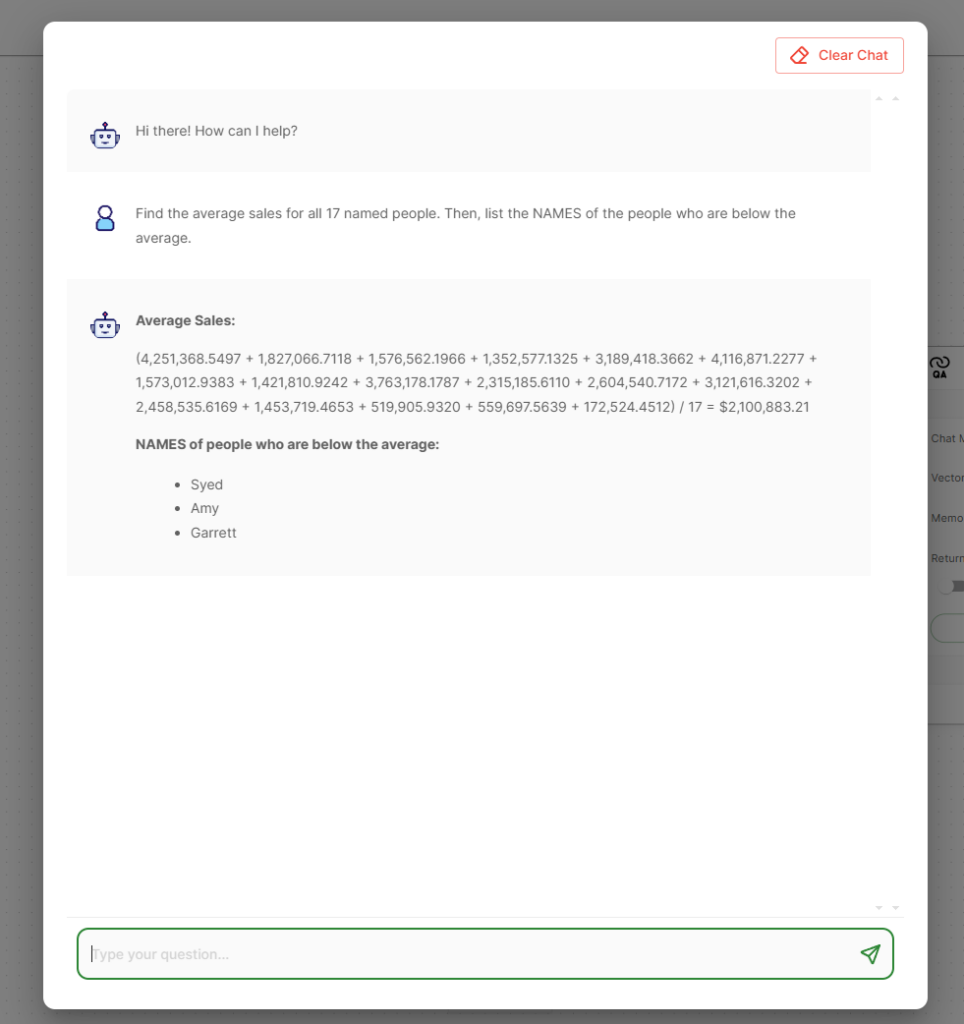
Here is an example dashboard in Logi Symphony using Google’s Gemma 2b model on Ollama to answer questions about the data.
All of the data and the LLM is completely secure with no information leaving the local cluster.
Setup
Deployment
The first step is to deploy Logi Symphony in Kubernetes as per the installation instructions (or use our SaaS offering). Once deployed, the next step is to add Ollama into the cluster. This can be done via their existing helm chart with the following run within the kubectl context:
helm repo add ollama https://otwld.github.io/ollama-helm/
helm repo update
helm install ollama ollama/ollama –set ollama.defaultModel=”gemma” –set persistentVolume.enabled=true
Ollama will now be deployed and accessible within the cluster as http://olama:11434 and already have the default gemma model preloaded. For this example, we also use a local embeddings model. To add that, run:
kubectl exec -it — ollama pull nomic-embed-text
Where ollama-pod-name is the name of the Ollama pod deployed above. Deployment is now complete!
Data
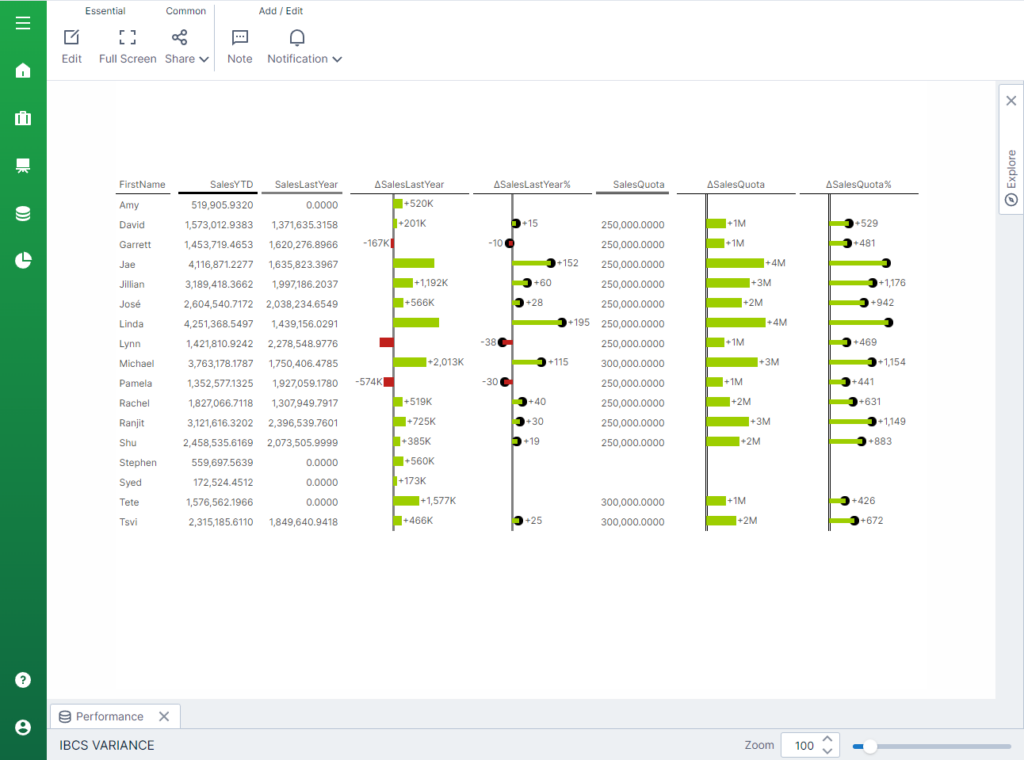
After deployment, create any visual or dashboard with any data you’d like in Logi Symphony, even Excel data. For this example I used Logi Symphony’s new built-in IBCS Variance control containing sales data for this year and last year.
Chat flow setup
After deployment and dashboard creation, the next step is to create the chat flow that will use Gemma to do RAG with data accessible from Logi Symphony. This data could be from any database you may have! As long as Logi Symphony can access it, Gemma will be able to as well.
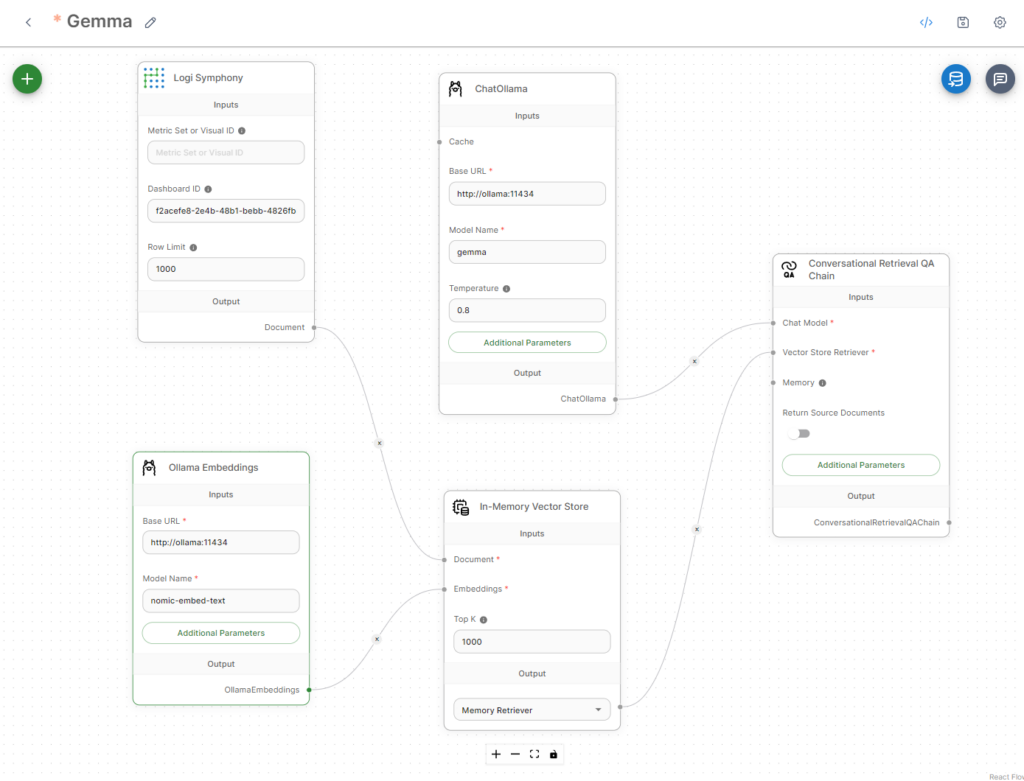
Final chat flow
Below is how the chat flow should look after being set up. Each of these nodes can be found in the + icon and added.
Setup steps
To set this up, start with a Conversational Retrieval QA Chain. To add this, click the + and expand Chains, then add it.
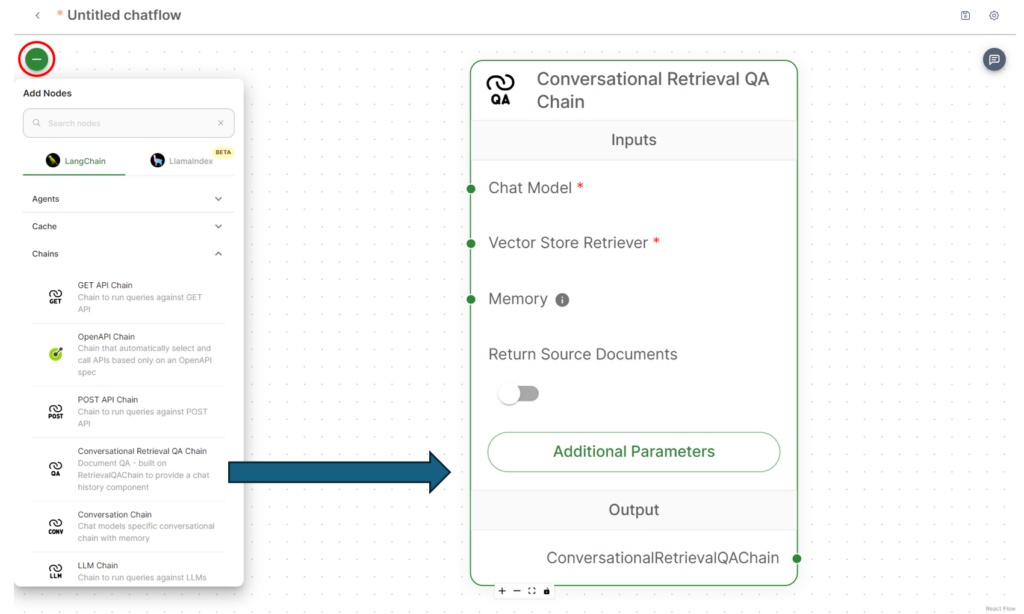
Follow the same steps to add the Chat Ollama from Chat Models, In-Memory Vector Store from Vector Stores, Logi Symphony from the document loaders, and finally Ollama Embeddings from embeddings.
Configuration notes
For Chat Ollama, you must specify the local URL of Ollama. This is often the local name within the Kubernetes cluster. If you used the same helm deployment as above, then it should be http://olama:11434.
In addition, the model must be specified. If using the default Gemma model, this can simply be gemma. The default gemma model is a 7b-instruct model that has been reduced in size through quantization. There is also a 2b-instruct model if resources are constrained, but it will be less accurate.
For Ollama Embeddings, you need to specify the same URL as the chat and the model. For this example, nomic-embed-text was used, and installation was done in the above deployment section.
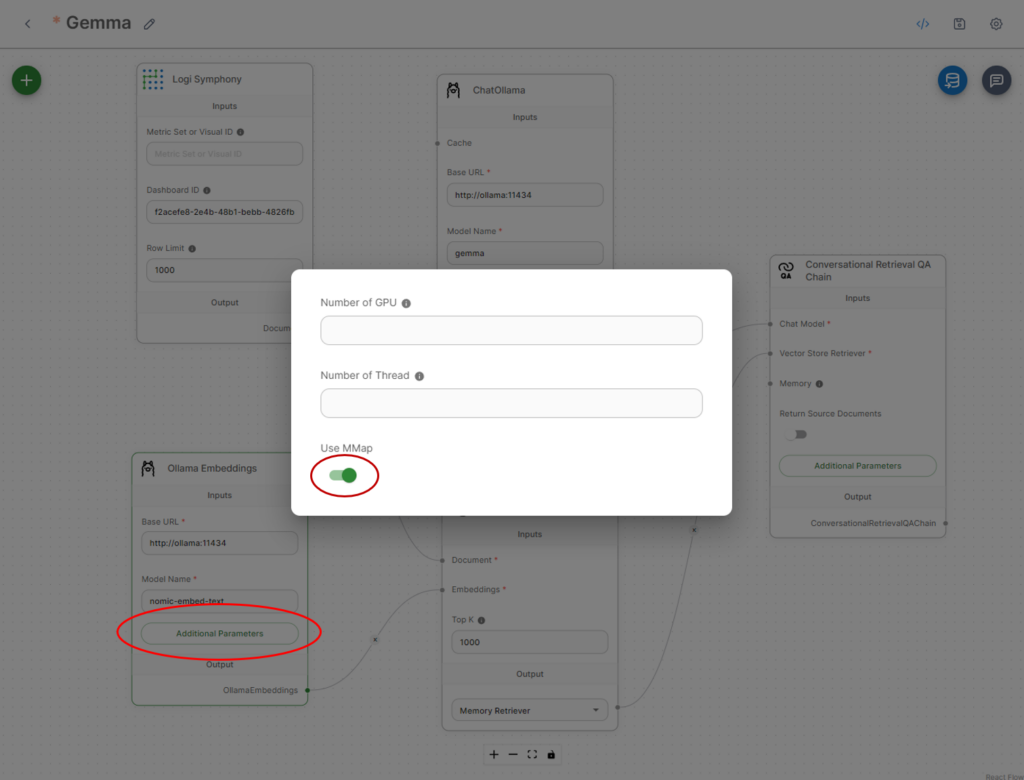
For embeddings, click Additional Parameters and ensure Use MMap is selected.
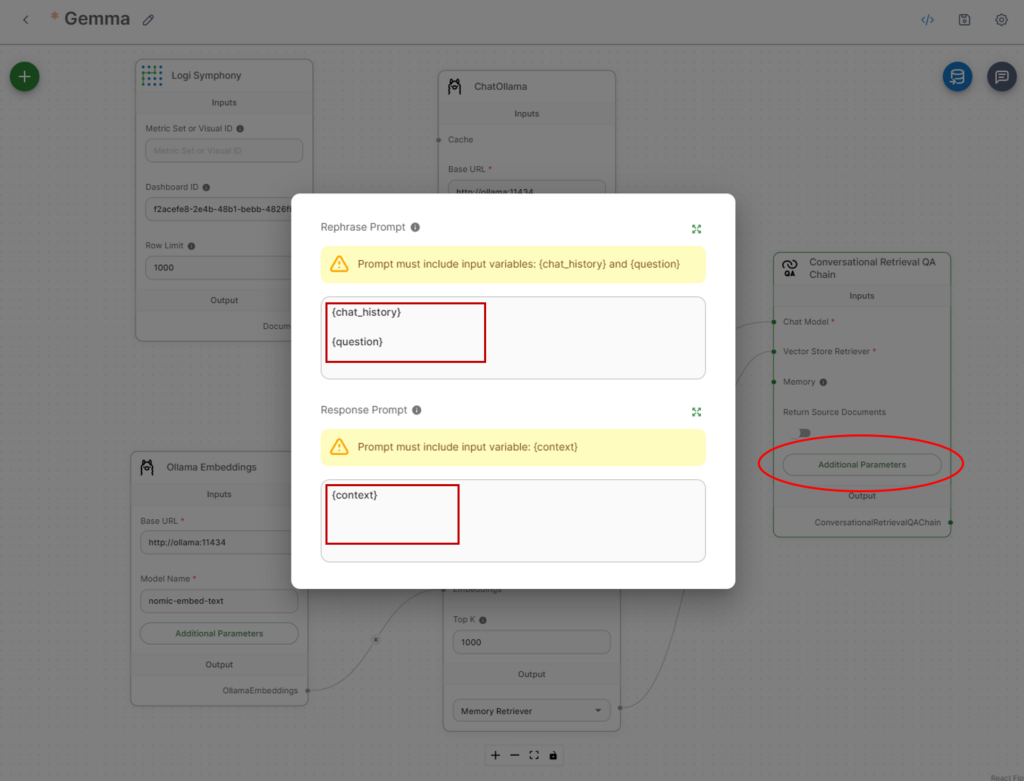
It’s also advised to modify the prompt as Gemma seems to do much better with a very simple prompt schema.
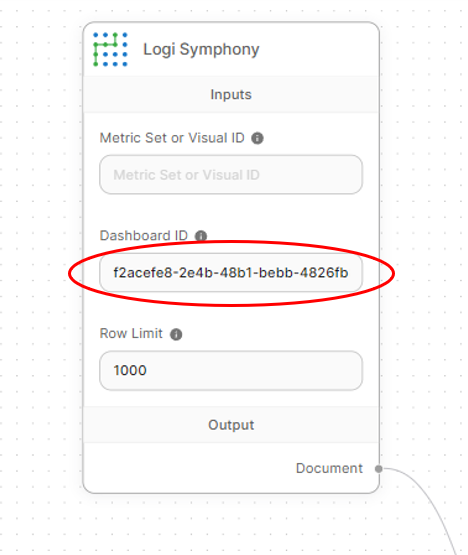
Lastly, set a dashboard or visual ID has been set on the Logi Symphony node so that data can be retrieved even when it’s not embedded. This is an optional step, but it allows using the chatbot when it’s not embedded within a dashboard.
Ask it questions!
Now that everything is setup, you can ask questions about the data right in Logi AI.
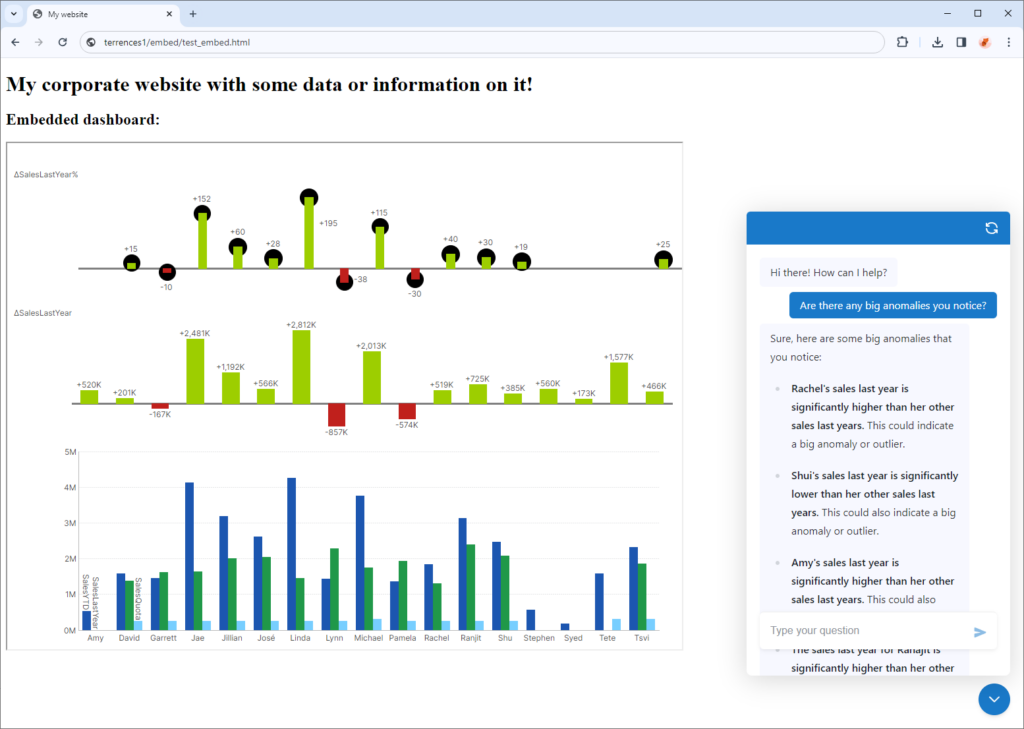
Embed it
The chatbot doesn’t have to be accessed only inside Logi AI, it can also be accessed right on the dashboard for anyone to use it, or even completely separately when embedded within a customer’s portal.