What’s the Difference? Relational vs Non-Relational Databases
What’s the difference between relational and non relational database? A relational database management system (RDBMS) organizes data into separate tables, allowing for flexible access and reassembly according to user-defined relational tables. In contrast, a non-relational database employs an architecture that does not rely on tables as its primary structure.
Imagine your data is a dog. In front of it, you place an Excel sheet and a Word doc. Which one will the dog go to?
It may be a little silly – but it’s a good way to understand exactly what kind of data works for the two main types of databases – relational and non-relational. Let’s go over the difference between relational databases and non relational database systems – as well as list some key questions every business should answer before choosing a relational database vs non relational database.
Relational vs Non-Relational Databases
The difference between relational and non-relational databases reflects the fundamental distinctions in data management systems. Relational databases organize data into interrelated tables, using a structured format that defines rows and columns within a schema, and rely on SQL (Structured Query Language) for structured querying. This setup is ideal for highly structured data requirements where data integrity and complex querying capabilities are essential. Relational databases excel at handling structured data and ensure consistency and accuracy across data entries through predefined relationships between tables. This makes them well-suited for applications in sectors like finance, healthcare, and ERP systems, where data accuracy, consistency, and support for intricate join operations are necessary.
On the other hand, Non-Relational databases, or NoSQL databases, offer flexible storage solutions that can accommodate various data types, such as documents, key-value pairs, column-family stores, and graph structures. This flexibility is advantageous when dealing with unstructured or semi-structured data that doesn’t fit neatly into a rigid schema. NoSQL databases are designed to handle scalable applications and support distributed clusters, allowing them to manage large volumes of data and high traffic loads. This scalability and adaptability make non-relational databases an ideal choice for applications that require rapid development and can benefit from schema-less design, such as social media platforms, IoT networks, and content management systems.
The choice between relational and non-relational databases ultimately depends on the need for either structured data integrity and complex querying or the need for scalability and flexibility in data handling. Relational databases are best suited for use cases where data structure and integrity are critical, while non-relational databases excel in environments where flexibility, rapid scaling, and handling of varied data types are more important.
What Are Relational Databases
Let’s go back to your “data dog.” Maybe it prefers the Excel sheet. Why? Because it fits nicely into rows and columns.
A relational database is one that stores data in tables. The relationship between each data point is clear and searching through those relationships is relatively easy. The relationship between tables and field types is called a schema. For relational databases, the schema must be clearly defined. From the perspective of a relational database, being an integral part of the 3-tier architecture highlights its pivotal role in ensuring data integrity, security, and efficient data management within the application’s Data Layer.
Relational databases are particularly effective for managing structured data, where data needs to fit neatly into predefined fields and rows. With their reliance on schemas, relational databases enforce strict data consistency, which helps ensure that all data entries adhere to a specific format and maintain integrity. This structure makes relational databases highly suitable for industries requiring accuracy and reliability, such as finance, healthcare, and logistics, where data validation is critical for day-to-day operations.
One of the major strengths of relational databases is their support for complex queries and join operations. SQL allows for powerful querying capabilities that can retrieve and combine data from multiple tables based on specific relationships, enabling in-depth analysis and reporting. This capability is especially useful in Customer Relationship Management (CRM) and Enterprise Resource Planning (ERP) systems, where data must often be pulled together from different areas to provide a complete picture.
Relational databases also support ACID properties (Atomicity, Consistency, Isolation, Durability), which are essential for maintaining reliable transactions. These properties prevent partial updates, ensuring that either all parts of a transaction are completed or none at all, making relational databases ideal for critical applications where data accuracy is non-negotiable.
Overall, the structured, schema-based approach of relational databases, combined with their robust querying and transaction capabilities, makes them a foundational tool for applications that depend on data integrity, consistent structure, and complex analysis.
Let’s look at an example:
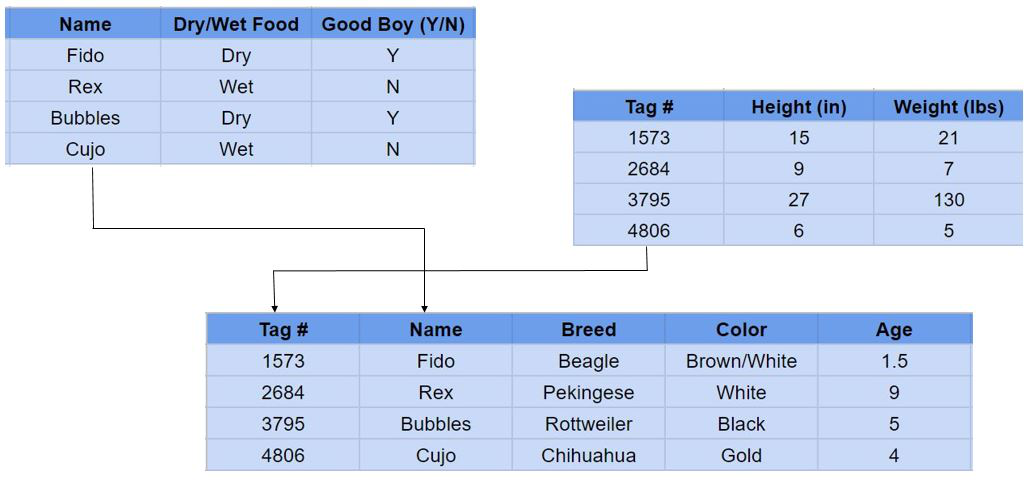
Here we see three tables all providing unique information on a specific dog. A relational database user can then obtain a view of the database to fit their needs. For example, I might want to view or report on all dogs over 100 pounds. Or you may wish to see which breeds eat dry food. Relational databases make answering questions like these relatively easy.
Relational databases are also called SQL databases. SQL stands for Structured Query Language and it’s the language relational databases are written in. SQL is used to execute queries, retrieve data, and edit data by updating, deleting, or creating new records.
Early adoption and widespread use keep SQL databases a popular data management system. This is in part due to the lack of training required for workers as many data scientists learn SQL early on. Let’s do a further breakdown of Relational vs Non-Relational Databases.
Examples of Popular Relational/SQL Databases
SQL Server
![]()
SQL Server is a relational database management system developed Microsoft. Relational database management systems offer multiple editions with varying features to target different users.
Pros: SQL Server boasts a rich user interface and can handle large quantities of data.
Cons: It can be expensive – with the Enterprise level costing thousands of dollars.
MySQL
![]()
First released in 1995, MySQL is a free and open-source software, and one of the most popular databases in the world. It is used by many high-traffic websites like Facebook and YouTube.
Pros: It’s free and open-source. There’s also a lot of documentation and online support.
Cons: It doesn’t scale very well. MySQL tends to stop working when it’s given too many operations at a given time.
PostgreSQL
![]()
Where MySQL is based on the relational model, PostgreSQL is based on the object-relational model. Another free and open-source database, PostgreSQL was released in 1996 with an emphasis on extensibility. It’s able to handle complicated data workloads due to its diversified extension functions.
Pros: Like we said, extensible. If you need additional features in PostgreSQL, you can add it yourself – a difficult task in most databases.
Cons: For beginners, installation and configuration can be difficult. There’s also not nearly as much documentation as more popular databases like MySQL.
What are Non-Relational Databases
Back to your “data dog.” This time, it went over to the Word doc. Why? All the open space! The data comes in all different shapes and sizes – it needs room to spread out.
A non-relational database is any database that does not use the tabular schema of rows and columns like in relational databases. Rather, its storage model is optimized for the type of data it’s storing, allowing data to be stored in diverse formats, such as documents, key-value pairs, graphs, or columns. This flexibility in structure makes non-relational databases ideal for applications with evolving or unstructured data that doesn’t fit neatly into predefined categories.

Non-relational databases are also known as NoSQL databases, which stands for “Not Only SQL.” Where relational databases rely solely on SQL for data management, non-relational databases can use a variety of other query languages, often specific to their data model. This multi-language capability allows NoSQL databases to handle data in ways that are tailored to different storage types, enhancing performance and scalability for specific use cases.
There are four different types of NoSQL databases:
Non-relational databases are particularly valuable when dealing with large-scale, complex, or rapidly changing data. They support various data models, such as:
1. Document-based databases
- These databases, like MongoDB and CouchDB, store data as documents (often in JSON or BSON format), making it easy to manage complex, hierarchical data within a single record. This model is particularly useful for content management systems, where each document may have unique structures and fields.
2. Key-value stores
- Databases like Redis and DynamoDB use a simple model where each item is stored as a key-value pair, allowing for quick data retrieval. Key-value stores are ideal for caching and session management due to their high-speed access.
3. Column-family stores
- Databases such as Cassandra and HBase store data by columns rather than rows, making them efficient for handling large amounts of structured data across distributed systems. This model is common in data analytics applications where operations are often performed on columns rather than rows.
4. Graph databases
- Databases like Neo4j and Amazon Neptune focus on relationships between data points, which is especially useful in social networks, recommendation engines, and fraud detection. By modeling entities as nodes and relationships as edges, graph databases allow complex, interconnected data to be efficiently managed and queried.
Non-relational databases are also designed for scalability and flexibility. Unlike traditional databases, which often require vertical scaling (adding more power to a single server), NoSQL databases typically allow for horizontal scaling by distributing data across multiple servers. This distributed approach enables applications to handle massive data volumes and high traffic loads, providing a cost-effective way to scale as data demands grow. This characteristic makes non-relational databases a preferred choice for cloud-native applications, real-time analytics, and big data environments.
NoSQL databases also offer high adaptability for agile development. In applications where data models evolve frequently or need to accommodate new data types quickly, non-relational databases provide a schema-less design that simplifies development. This flexibility allows teams to make adjustments without downtime or complex migrations, making NoSQL databases an attractive option for startups, MVPs (Minimum Viable Products), and projects where rapid iteration is essential.
Overall, non-relational databases provide a powerful, scalable, and flexible solution for applications that manage diverse data types, high-velocity data, and complex relationships. Their ability to handle unstructured data efficiently and scale with ease makes them a foundational technology for modern, data-driven applications.
Examples of Popular Non-Relational/NoSQL Databases
MongoDB
![]()
MongoDB is a document store and currently the most popular NoSQL database engine in use. It uses JSON-like documents to store data and is run over multiple servers. MongoDB allows for auto-sharding which is a type of database partitioning that separates very large databases into smaller, faster, more easily managed parts called data shards.
Pros: MongoDB is very easy to setup and provides a lot of professional support.
Cons: They don’t allow joins. Joins are used to combine data or rows from two or more tables based on a common field between them. MongoDB does have a LOOKUP function but tells its users not to rely on them.
Redis
![]()
Redis – Remote Dictionary Server – is a key-value store. It supports different kinds of abstract data structures such as strings, lists, maps, sets, sorted sets, and more. It’s also open-source.
Pros: It supports a large variety of data types and is easy to install.
Cons: Like MongoDB, it doesn’t support joins. It also requires knowledge of Lua, a high-level programming language.
When to use relational vs. non-relational databases
When deciding between relational and non-relational databases for your project, it’s essential to consider the specific needs and characteristics of your data, as well as how you plan to use it. Here is a detailed exploration of the situations when one might be preferred over the other:
When to Use Relational Databases
Relational databases are a powerful choice for data management when a high level of structure, consistency, and data integrity is required. With a well-defined schema and strict data relationships, relational databases excel in applications where data accuracy and sophisticated querying are paramount.
Structured Data Requirements
Relational databases are the preferred option when dealing with highly structured data that follows a consistent format. In scenarios where each piece of data neatly fits into predefined rows and columns, relational databases allow for precise organization and data entry validation. This structure is ideal for enterprise applications, transactional systems, and any setting where a detailed schema can be established upfront. Relational databases enforce data integrity through schema rules, ensuring data remains consistent and organized across tables.
Complex Queries and Join Operations
Relational databases are designed to handle complex queries that span multiple tables and require advanced join operations. When applications need to retrieve data across different tables with precise conditions, relational databases provide robust support through Structured Query Language (SQL). For instance, in systems like customer relationship management (CRM) platforms or financial reporting, where data is interconnected and often queried in sophisticated ways, relational databases allow for efficient and accurate query execution.
ACID Transactions
Relational databases support ACID (Atomicity, Consistency, Isolation, Durability) transactions, a set of properties that ensures reliable data handling in multi-step processes. These properties are essential for applications in fields like finance, banking, and e-commerce, where a high degree of data accuracy and consistency is critical. By supporting ACID transactions, relational databases maintain data integrity even in the event of system errors or crashes, making them suitable for mission-critical applications where data accuracy is non-negotiable.
Mature Tools and Ecosystem
With decades of development, relational databases have a well-established ecosystem of tools, support, and resources. This maturity offers extensive solutions for data backup, monitoring, and performance optimization. Tools like Oracle Database, MySQL, and Microsoft SQL Server have robust community and commercial support, enabling easy integration with analytics platforms, business intelligence tools, and ETL (Extract, Transform, Load) processes. This established ecosystem simplifies operations and provides reliability for enterprise environments requiring stable, long-term data solutions.
When to Use Non-Relational Databases
Non-relational databases, or NoSQL databases, offer the flexibility and scalability required for managing diverse and fast-growing datasets. They are designed to handle varying data structures, making them ideal for applications with rapid development needs and large-scale data requirements.
Flexible Data Models
Non-relational databases are well-suited for handling unstructured or semi-structured data, offering flexibility that relational databases lack. They don’t require a rigid schema, allowing data structures to evolve over time without modifying the database structure. This makes NoSQL databases an excellent choice for applications with diverse data sources, such as social media platforms, where data formats can vary and adapt based on new features or user-generated content.
Scalability
NoSQL databases are designed to scale horizontally, meaning they can distribute data across multiple servers or clusters. This makes them highly effective for applications that anticipate high volumes of data and traffic, such as large-scale web applications or IoT platforms. By leveraging distributed systems, non-relational databases allow for cost-effective scaling without the limitations of traditional, vertically scaled relational databases. This scalability is beneficial for businesses expecting rapid growth or handling big data scenarios.
High Performance with Simple Queries
For applications with straightforward query patterns and high performance needs, non-relational databases are an optimal solution. In cases like caching, session management, or content delivery, NoSQL databases like key-value stores and document databases deliver fast read and write capabilities. This speed is particularly useful for real-time applications where latency must be minimal, and simple, direct data retrieval is a priority.
Rapid Development
The schema-less structure of NoSQL databases supports rapid iteration, making them ideal for projects where the data model might evolve over time. In agile development environments, where features are frequently added and data requirements change, non-relational databases allow developers to adjust data structures quickly without the constraints of a rigid schema. This flexibility makes NoSQL databases an attractive choice for startups, MVPs (minimum viable products), and other applications with evolving data needs.
Non-relational databases offer the flexibility and performance that modern, data-rich applications demand, making them essential for scaling dynamically and adapting to changing requirements.
Relational vs. Non-Relational Database: Pros and Cons
When deciding between relational and non-relational databases, understanding the strengths and limitations of each type is crucial. Both database types offer unique advantages, so the best choice depends on the application’s specific requirements and data handling needs.
Relational Database Pros and Cons
Pros:
- Data Integrity and Consistency: Relational databases enforce data accuracy through strict schemas and ACID compliance, making them ideal for applications where data integrity is critical, such as finance and healthcare.
- Complex Querying Capabilities: SQL allows for powerful queries and joins across multiple tables, enabling detailed analysis and complex data retrieval. This makes relational databases well-suited for reporting and analytical tasks.
- Mature Ecosystem: Relational databases have a long history, resulting in robust support, tools, and resources for backup, monitoring, and optimization, making them highly reliable in enterprise environments.
Cons:
- Rigid Schema: Relational databases require a predefined schema, which can make it challenging to adapt to changing data needs or accommodate unstructured data.
- Scalability Limitations: Most relational databases rely on vertical scaling (adding more power to a single server), which can become costly and less efficient for large-scale applications.
- Performance with High-Volume Data: Relational databases can experience performance bottlenecks when dealing with massive data volumes or high write speeds, making them less suitable for real-time analytics or big data environments.
Non-Relational Database Pros and Cons
Pros:
- Flexibility in Data Structure: Non-relational databases use schema-less designs, allowing for more flexible and adaptive data storage. This is advantageous for applications with diverse or rapidly evolving data types, like social media platforms.
- Horizontal Scalability: NoSQL databases are designed for horizontal scaling, which distributes data across multiple servers. This makes them highly efficient for managing large datasets and high traffic loads, providing a cost-effective solution for scaling applications.
- High Performance for Simple Queries: Non-relational databases excel at fast data retrieval for straightforward queries, making them ideal for caching, real-time data processing, and applications that prioritize speed over complex queries.
Cons:
- Limited Querying Capabilities: While NoSQL databases support various data models, they often lack the complex querying capabilities of SQL, making them less suitable for applications requiring intricate joins and data relationships.
- Less Consistency: Many NoSQL databases prioritize availability and partition tolerance over strict data consistency, which may not meet the standards of applications that require ACID compliance.
- Less Mature Ecosystem: Non-relational databases are newer than relational ones, so their toolsets and community support are less established. This can pose challenges for long-term maintenance and integration with other systems.
Relational databases are ideal for applications that require strong data consistency, complex querying, and reliability. Non-relational databases, on the other hand, offer greater flexibility and scalability, making them suited to dynamic, high-volume data environments. The choice ultimately depends on the nature of the data, application requirements, and scalability needs.
Relational vs Non Relational Database
To summarize the difference between relational and non-relational databases: relational databases store data in rows and columns like a spreadsheet, while non-relational databases don’t. Instead, non-relational databases use one of four storage models—document-based, key-value, column-family, or graph—that best fit the type of data being stored.
Relational databases are ideal for applications requiring structured data with a high level of integrity and support for complex SQL queries. They excel in scenarios needing strict data consistency, as they organize data through a predefined schema. Non-relational databases, on the other hand, offer flexibility for unstructured or evolving data and scale horizontally across distributed systems. They are well-suited for handling large, diverse, or dynamic data sets where rapid development and scalability are key priorities.
Questions to Answer Before Choosing a Database
What type of data will you be analyzing?
Does your data fit comfortably in rows and columns? Or is it better suited in a more flexible space? The answer will tell you whether you need a relational or non-relational database.
How much data are you dealing with?
A good rule of thumb is this – the bigger the data set, the more likely a non-relational database is a better fit. Non-relational databases can store unlimited sets of data with any type and have the flexibility to change the data type.
But relational databases work best when performing intensive read/write operations on small- or medium-sized data sets.
What kind of resources can you devote to the setup and maintenance of your database?
Here’s another good rule of thumb – the smaller your engineering team, the more likely a relational database is a better fit. Why? For one, relational databases take less time to manage. Also, SQL is a more well-known query language. It’s more likely your team already knows it.
Non-relational databases may require more programming knowledge – meaning your team may have to learn other types of query languages. Or you’ll need to hire someone with a code-heavier background.
Do you need real-time data?
There’s a serious buzz around real-time analytics. The competitive edge it brings and its impact on decision-making cannot be understated. However, it’s important to note that not every organization needs real-time data. Maybe your data doesn’t change that much. Maybe you’re more interested in analyzing past data sets. In that case, relational databases work well.
Logi Symphony: Leverage Your Entire Cloud into Reports & Dashboards
Logi Symphony is a product offering/bundle by insightsoftware that was purpose-built to be embedded inside your application and deliver self-service analytics and reporting to your end users. Logi Symphony empowers simple and power users alike to create robust reports and discover actionable insights for making better business decisions.
Product Managers augment their product offering with Logi Symphony to connect to virtually any data source directly or by leveraging REST APIs. Additionally, Logi Symphony contains an ETL-lite data layer that provides numerous features to solve data-related issues you might experience with your embedded Reporting and BI needs. Using the Logi Symphony data layer, you can:
- Boost and optimize data performance with patented in-memory cubes.
- Increase performance and data reliability with built-in data warehousing and automatic data indexing.
- Augment and extend data for better analysis using built-in transformations to solve common data issues.
- Enable predictive analytics, AI, and machine learning or custom data rules on top of your data by leveraging programming languages such as C#, Python, or R.
- Create a tailored user experience by securing data by user with row/column level security.