What’s the Difference? Relational vs Non-Relational Databases
What’s the difference between relational and non relational database? A relational database management system (RDBMS) organizes data into separate tables, allowing for flexible access and reassembly according to user-defined relational tables. In contrast, a non-relational database employs an architecture that does not rely on tables as its primary structure.
Imagine your data is a dog. In front of it, you place an Excel sheet and a Word doc. Which one will the dog go to?
It may be a little silly – but it’s a good way to understand exactly what kind of data works for the two main types of databases – relational and non-relational. Let’s go over the difference between relational databases and non relational database systems – as well as list some key questions every business should answer before choosing a relational database vs non relational database.
Relational vs Non-Relational Databases
The difference between relational vs Non-Relational Databases reflects the fundamental differences in data management systems: Relational databases organize data into interrelated tables and rely on SQL for structured querying, while Non-Relational databases, or NoSQL, offer flexible storage solutions like document or key-value stores, ideal for unstructured data and scalable applications. The choice between them depends on the need for either structured data integrity and complex querying or scalability and flexibility in data handling.
What Are Relational Databases
Let’s go back to your “data dog.” Maybe it prefers the Excel sheet. Why? Because it fits nicely into rows and columns.
A relational database is one that stores data in tables. The relationship between each data point is clear and searching through those relationships is relatively easy. The relationship between tables and field types is called a schema. For relational databases, the schema must be clearly defined. From the perspective of a relational database, being an integral part of the 3-tier architecture highlights its pivotal role in ensuring data integrity, security, and efficient data management within the application’s Data Layer.
Let’s look at an example:
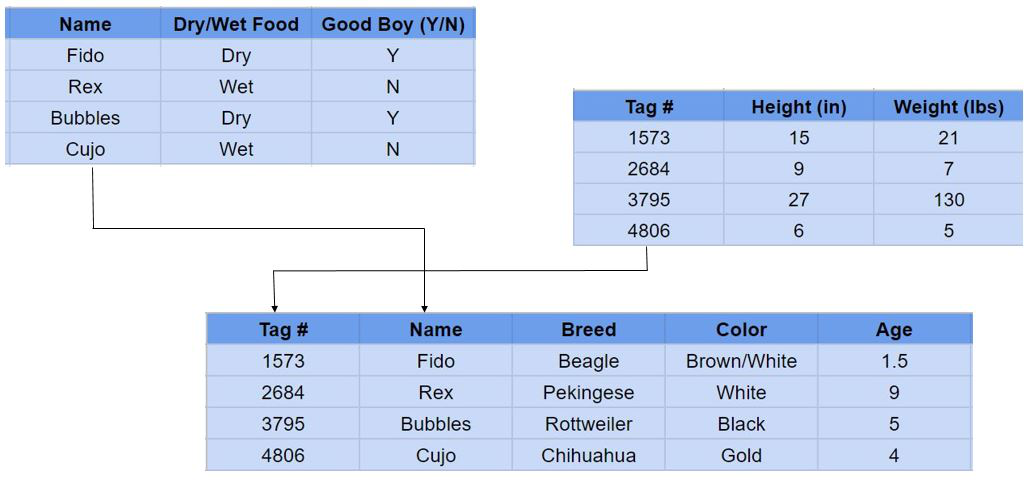
Here we see three tables all providing unique information on a specific dog. A relational database user can then obtain a view of the database to fit their needs. For example, I might want to view or report on all dogs over 100 pounds. Or you may wish to see which breeds eat dry food. Relational databases make answering questions like these relatively easy.
Relational databases are also called SQL databases. SQL stands for Structured Query Language and it’s the language relational databases are written in. SQL is used to execute queries, retrieve data, and edit data by updating, deleting, or creating new records.
Early adoption and widespread use keep SQL databases a popular data management system. This is in part due to the lack of training required for workers as many data scientists learn SQL early on. Let’s do a further breakdown of Relational vs Non-Relational Databases.
Examples of Popular Relational/SQL Databases
SQL Server
![]()
SQL Server is a relational database management system developed Microsoft. Relational database management systems offer multiple editions with varying features to target different users.
Pros: SQL Server boasts a rich user interface and can handle large quantities of data.
Cons: It can be expensive – with the Enterprise level costing thousands of dollars.
MySQL
![]()
First released in 1995, MySQL is a free and open-source software, and one of the most popular databases in the world. It is used by many high-traffic websites like Facebook and YouTube.
Pros: It’s free and open-source. There’s also a lot of documentation and online support.
Cons: It doesn’t scale very well. MySQL tends to stop working when it’s given too many operations at a given time.
PostgreSQL
![]()
Where MySQL is based on the relational model, PostgreSQL is based on the object-relational model. Another free and open-source database, PostgreSQL was released in 1996 with an emphasis on extensibility. It’s able to handle complicated data workloads due to its diversified extension functions.
Pros: Like we said, extensible. If you need additional features in PostgreSQL, you can add it yourself – a difficult task in most databases.
Cons: For beginners, installation and configuration can be difficult. There’s also not nearly as much documentation as more popular databases like MySQL.
What are Non-Relational Databases
Back to your “data dog.” This time, it went over to the Word doc. Why? All the open space! The data comes in all different shapes and sizes – it needs room to spread out.
A non-relational database is any database that does not use the tabular schema of rows and columns like in relational databases. Rather, its storage model is optimized for the type of data it’s storing.

Non-relational databases are also known as NoSQL databases which stands for “Not Only SQL.” Where relational databases only use SQL, non-relational databases can use other types of query language.
There are four different types of NoSQL databases:
-
Document-oriented databases
– Also known as a document store, this database is designed for storing, retrieving and managing document-oriented information. Document databases usually pair each key with a complex data structure (called a document).
-
Key-Value Stores
– This is a database that uses different keys where each key is associated with only one value in a collection. Think of it as a dictionary. This is one of the simplest database types among NoSQL databases.
-
Wide-Column Stores
– this database uses tables, rows, and columns, but unlike a relational database, the names and format of the columns can vary from row to row in the same table.
-
Graph Stores
– A graph database uses graph structures for semantic queries with nodes, edges, and properties to represent and store data.
Non-relational databases are becoming more popular as more and more businesses begin to leverage big data for analysis and reporting. Since critical data doesn’t always fit well into a pre-defined schema, NoSQL databases allow more flexibility.
Examples of Popular Non-Relational/NoSQL Databases
MongoDB
![]()
MongoDB is a document store and currently the most popular NoSQL database engine in use. It uses JSON-like documents to store data and is run over multiple servers. MongoDB allows for auto-sharding which is a type of database partitioning that separates very large databases into smaller, faster, more easily managed parts called data shards.
Pros: MongoDB is very easy to setup and provides a lot of professional support.
Cons: They don’t allow joins. Joins are used to combine data or rows from two or more tables based on a common field between them. MongoDB does have a LOOKUP function but tells its users not to rely on them.
Redis
![]()
Redis – Remote Dictionary Server – is a key-value store. It supports different kinds of abstract data structures such as strings, lists, maps, sets, sorted sets, and more. It’s also open-source.
Pros: It supports a large variety of data types and is easy to install.
Cons: Like MongoDB, it doesn’t support joins. It also requires knowledge of Lua, a high-level programming language.
When to use relational vs. non-relational databases
When deciding between relational and non-relational databases for your project, it’s essential to consider the specific needs and characteristics of your data, as well as how you plan to use it. Here is a detailed exploration of the situations when one might be preferred over the other:
When to Use Relational Databases
Structured Data Requirements
Use relational databases when your data is highly structured and consistent. This is ideal for scenarios where you can define a schema upfront and where each piece of data (row) neatly fits into a predefined model (table).
Complex Queries and Join Operations
If your application requires the ability to perform complex queries that involve multiple tables and necessitate sophisticated join operations, relational databases excel in these areas. They are designed to handle intricate SQL queries efficiently.
ACID Transactions
Projects that require Atomicity, Consistency, Isolation, and Durability (ACID) properties for transactions should opt for relational databases. These properties ensure data integrity during transaction processing, making them suitable for banking, financial services, and any application where data consistency is critical.
Mature Tools and Ecosystem
Relational databases benefit from a long history of development, resulting in a rich ecosystem of tools, extensions, and integrations. This maturity can provide more robust solutions for backup, monitoring, and performance optimization.
When to Use Non-Relational Databases
Flexible Data Models
Non-relational databases, also known as NoSQL databases, are ideal when dealing with unstructured or semi-structured data. They allow for a flexible data model that can accommodate changes and variations in data structure without requiring a predefined schema.
Scalability
If you expect your application to handle massive volumes of data and high traffic loads, non-relational databases are often more easily scaled. They are designed to scale out using distributed clusters of hardware, which can provide cost-effective scalability.
High Performance with Simple Queries
For applications where the query patterns are relatively simple but need to be executed with high speed and efficiency, non-relational databases can provide superior performance. This is particularly true for key-value stores and document databases where operations are typically more straightforward than complex SQL queries.
Rapid Development
Projects that require quick iterations and where the data model might change frequently may benefit from the schema-less nature of non-relational databases. This flexibility can significantly speed up development cycles in agile and evolving projects.
Relational vs Non Relational Database
To summarize the difference between relational and non relational database: relational databases store data in rows and columns like a spreadsheet while non-relational databases store data don’t, using a storage model (one of four) that is best suited for the type of data it’s storing.
Questions to Answer Before Choosing a Database
What type of data will you be analyzing?
Does your data fit comfortably in rows and columns? Or is it better suited in a more flexible space? The answer will tell you whether you need a relational or non-relational database.
How much data are you dealing with?
A good rule of thumb is this – the bigger the data set, the more likely a non-relational database is a better fit. Non-relational databases can store unlimited sets of data with any type and have the flexibility to change the data type.
But relational databases work best when performing intensive read/write operations on small- or medium-sized data sets.
What kind of resources can you devote to the setup and maintenance of your database?
Here’s another good rule of thumb – the smaller your engineering team, the more likely a relational database is a better fit. Why? For one, relational databases take less time to manage. Also, SQL is a more well-known query language. It’s more likely your team already knows it.
Non-relational databases may require more programming knowledge – meaning your team may have to learn other types of query languages. Or you’ll need to hire someone with a code-heavier background.
Do you need real-time data?
There’s a serious buzz around real-time analytics. The competitive edge it brings and its impact on decision-making cannot be understated. However, it’s important to note that not every organization needs real-time data. Maybe your data doesn’t change that much. Maybe you’re more interested in analyzing past data sets. In that case, relational databases work well.
Logi Symphony: Leverage Your Entire Cloud into Reports & Dashboards
Logi Symphony is a product offering/bundle by insightsoftware that was purpose-built to be embedded inside your application and deliver self-service analytics and reporting to your end users. Logi Symphony empowers simple and power users alike to create robust reports and discover actionable insights for making better business decisions.
Product Managers augment their product offering with Logi Symphony to connect to virtually any data source directly or by leveraging REST APIs. Additionally, Logi Symphony contains an ETL-lite data layer that provides numerous features to solve data-related issues you might experience with your embedded Reporting and BI needs. Using the Logi Symphony data layer, you can:
- Boost and optimize data performance with patented in-memory cubes.
- Increase performance and data reliability with built-in data warehousing and automatic data indexing.
- Augment and extend data for better analysis using built-in transformations to solve common data issues.
- Enable predictive analytics, AI, and machine learning or custom data rules on top of your data by leveraging programming languages such as C#, Python, or R.
- Create a tailored user experience by securing data by user with row/column level security.