MPP & Columnar Databases

Many SQL databases designed for large data volumes are built on column-store and massively parallel processing (MPP) architectures.
What is an MPP Database?
SQL server is a symmetric multiprocessing solution (SMP). Essentially this means it uses one server. Many databases designed for data warehouses that will support big data projects use massively parallel processing (MPP) architectures to provide scalability and high performance queries on large data volumes. MPP architectures consist of many servers running in parallel to distribute processing and input/output (I/O) loads.
MPP systems feature multiple servers
Most MPP databases leverage a “shared-nothing architecture” where each server operates independently and controls its disk and memory. They distribute data onto dedicated disk or solid-state drive (SSD) storage units connected to each server in the appliance. (A data warehouse appliance includes an integrated set of servers, storage, operating systems, and databases.) This allows them to resolve an SQL query by scanning data on each server in a parallel way. This divide-and-conquer approach scales linearly as new servers are added into the architecture and delivers high performance.
What is a Column-Oriented Database?
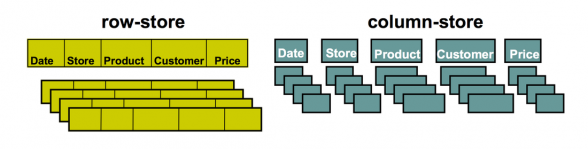
For querying large data sets column-store databases are more efficient than row-store.
Traditional relational database management software systems designed for transaction processing store data by row, as this provides most efficient operation when inserting, deleting or updating an individual row. In contrast, a column-oriented database stores data tables by column instead of by row. Both column and row databases can use traditional query languages like SQL to load data and perform queries.
Nevertheless, a major bottleneck in handling big data is disk access. Columnar databases boost performance by reducing the amount of data that needs to be read from disk by efficiently compressing similar columnar data and reading only the data necessary to answer the query.
By storing data in columns rather than rows, the database can more quickly access and aggregate the data it needs to answer a query rather than scanning and discarding unwanted data in rows. As a result, the kinds of aggregate queries typically used when analyzing very large data sets run dramatically faster.
MPP versus Hadoop
When most people think about big data, Hadoop and MapReduce, as well as other modern processing frameworks come to mind. So, does that mean that Hadoop is a replacement for MPP databases? No, in fact, there are striking similarities between the way all three work.
With Hadoop, MapReduce is used to break large chunks of data into smaller batches to process separately via a cluster of computing nodes. This is distributed query processing, which is exactly what MPP does.
MPP is often deployed on expensive, specialized hardware tuned for CPU, storage, and network performance. MapReduce and Hadoop typically run on clusters of servers that use commodity hardware (disks). It is usually less expensive to scale a Hadoop/MapReduce deployment than an MPP appliance.
Also, MapReduce logic is implemented via Java code, whereas MPP products are queried with SQL. Of course, Hive offers an SQL abstraction over MapReduce. But natively, they are different at the code level. Nevertheless, MPP and Hadoop/MapReduce can both be looked at as big data technologies.
Logi Composer on MPP and Columnar Databases
While Logi Composer excels with big data and its uses cases, which for most people are synonymous with Hadoop, Logi Composer is not only for big data. Data-driven enterprises have significant data assets in relational databases, data warehouses, and other traditional systems. For this reason, Logi Composer also enables data discovery with traditional SQL-based sources such as Oracle, SQL Server, PostgreSQL, MySQL, as well as MPP solutions like the Amazon Aurora and column-store databases like Vertica, Teradata, and others.
Logi Composer and SQL Databases
Logi Composer features certified support for the following SQL databases, and more:
-
- MemSQL
- Vertica
- Teradata Database (on-premise) and Teradata Database on AWS
- Teradata Appliance for Hadoop on Cloudera CDH and Hortonworks HDP
- Microsoft SQL Server
- Oracle Database
- PostgreSQL
- MySQL
Enterprise data architectures almost always contain a combination of SQL database sources as well as modern sources like Apache Hadoop and Apache Spark. Logi Composer enables exploration across all these data sources with the ability to blend data on the fly using Logi Composer Fusion.
The unique features of Logi Composer that support visual analytics for big data can also be applied to traditional data. For example, Logi Composer Fusion can combine modern and traditional sources without having to move data to a common data store. Data Sharpening, micro-queries, result set caching, and Data DVR all add extra performance and capabilities for visual analytics on traditional SQL data sources.

Meet Logi Composer
Watch Now